간단한 프로그램 분석을 통해 다음 두가지를 보여주고자 합니다.
(1) 리눅스에 Purify가 제대로 설치되어 있는 지 확인합니다.
(2) 작고 간단한 프로그램이지만 에러가 발생하기가 쉬우며 어떤 수정이 필요한지 보여줍니다.
아래 conv.c는 화씨를 섭씨로 변경하는 C 프로그램으로 Kernighan 및 Ritchie의 The C Programming Language에 예시된 프로그램을 조금 변경한 것입니다.
#include <stdio.h>
#include <stdlib.h>
#include <malloc.h>
main()
{
int *fahr;
fahr = (int *)malloc(sizeof(int));
int celsius;
int lower, upper, step;
celsius = lower + 10;
lower = 0; /* lower limit of temperature table */
upper = 300; /* upper limit */
step = 20; /* step size */
*fahr = lower;
while(*fahr <= upper){
celsius = 5 * (*fahr - 32) / 9;
printf("%d\t%d\n", *fahr, celsius);
*fahr = *fahr + step;
}
}
Purify를 이용해 이 프로그램을 분석하기 위해, 링크 커맨드 앞에 purify를 추가함으로써 프로그램에 삽입을 합니다. Purify 분석 메세지를 상세화하기 위해서 -g 옵션을 추가할 수 있습니다:
purify gcc [-g] conv.c
그림 1: gcc 컴파일러와 Purify를 이용한 conv.c 프로그램 빌드 및 삽입

만약 프로그램 컴파일 및 링크를 단계별로 수행할 경우에는 링크 라인에만 purify를 명시합니다:
컴파일 라인: gcc -c [-g] conv.c
링크 라인: purify gcc [-g] conv.o
Rational PurifyPlus for Linux and UNIX에서 지원하는 컴파일러 목록은 아래와 같습니다.
출처: http://www-01.ibm.com/software/awdtools/purifyplus/unix/sysreq/
| Operating System | Software | Hardware |
|---|---|---|
| Solaris® 10 base through 5/09 Solaris 9 base through 9/05 Solaris 8 base through 2/04 | Sun C/C++ 5.3 through 5.10 GNU gcc/g++ 4.0 through 4.4 GNU gcc/g++ 3.0 through 3.4 | Sun UltraSPARC® |
| Solaris 10 6/06 through 5/09 | Sun C/C++ 5.8 through 5.10 GNU gcc/g++ 4.0 through 4.4 GNU gcc/g++ 3.4 | AMD64™ Intel® 64 |
| RHEL 5 (Server/Desktop) base through 5.4 RHEL 4 (AS/ES/WS) base through 4.8 RHEL 3 (AS/ES/WS) base through U9 SLES 11 base SLES 10 base through SP2 SLES 9 base through SP4 | GNU gcc/g++ 4.0 through 4.4 GNU gcc/g++ 3.2 through 3.4 Intel icc 11.0 Intel icc 10.1 | Intel IA-32 |
| RHEL 5 (Server/Desktop) base through 5.4 RHEL 4 (AS/ES/WS) base through 4.8 SLES 11 base SLES 10 base through SP2 SLES 9 base through SP4 | GNU gcc/g++ 4.0 through 4.4 GNU gcc/g++ 3.2 through 3.4 Intel icc 11.0 Intel icc 10.1 | AMD64 Intel 64 |
| AIX® 6.1 base through TL3 AIX 5L v5.3 TL5 through TL9 | IBM® XL C/C++ 10.1 IBM XL C/C++ 9.0 IBM XL C/C++ 8.0 IBM XL C/C++ 7.0 GNU gcc/g++ 3.4 | IBM POWER4 IBM POWER5 IBM POWER6 |
7.0.1.0-002
Solaris
- Solaris 10 update 8
- Solaris Studio 12.1
- gcc 4.5
- gdb 6.8, 6.9, 7.0, 7.1
- Red Hat Enterprise Linux 5.5 (Server/Desktop)
- SUSE Linux Enterprise Server 10 SP3
- gcc 4.5
- gdb 6.8, 6.9, 7.0, 7.1
- icc 11.1
- AIX 6.1 TL4
- AIX 5.3 TL10, TL11
이제 삽입된 프로그램을 실행하여 결과를 보도록 하겠습니다. 실행 결과가 그림 2처럼 커맨드 라인에 표시되는 동안, Purify는 분석 결과를 그림 3처럼 윈도우에 표시를 합니다.
그림 2: 프로그램 실행 출력 화면
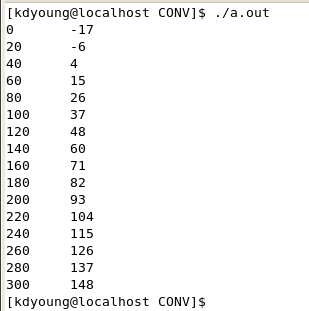
그림 3: 프로그램 실행 분석 화면

탐지된 에러와 누수 정보를 보다 자세히 보려면 그림 4처럼 해당 메뉴항목을 확장합니다. Purify는 문제가 발생한 지점을 자세히 보여줍니다.
그림 4: 문제에 대한 상세 보기 (-g 옵션을 사용하지 않은 경우)
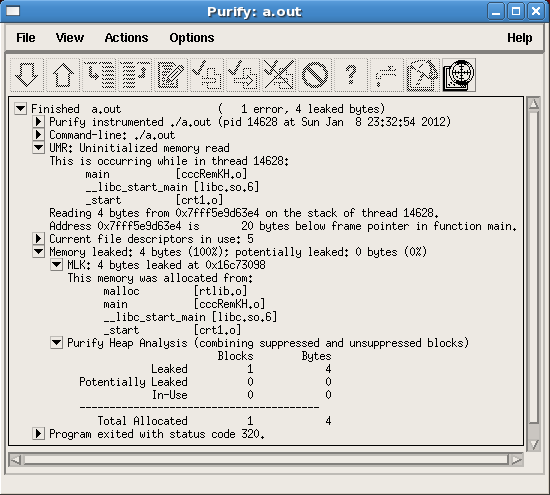
그림 4-1: 문제에 대한 상세 보기 (-g 옵션을 사용한 경우)
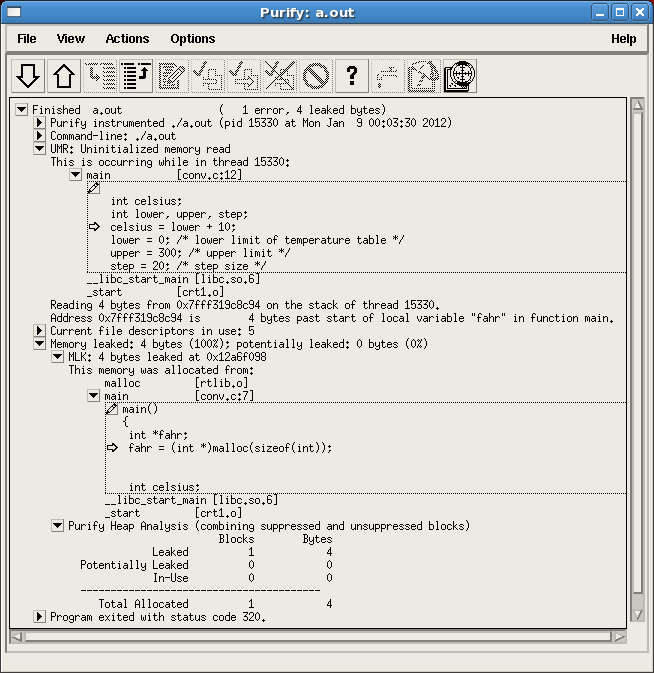
문제 해결에 필요한 도움말이 필요할 경우에는 에러(예 그림 4, "UMR: Uninitialized memory read")를 선택한 후 물음표를 클릭합니다.혹은 Actions 메뉴에서 그림 5처럼 Explain message를 선택합니다.
그림 5: Actions 메뉴의 메뉴 항목

그림 6처럼 UMR 에러 메시지 관련 정보가 나타납니다.
그림 6: UMR 에러 메세지에 대한 설명
도움말을 통해서, Purify가 탐지한 문제에 대한 해결책을 아래 처럼 결정할 수 있습니다:
그림 4: 문제에 대한 상세 보기 (-g 옵션을 사용하지 않은 경우)

그림 4-1: 문제에 대한 상세 보기 (-g 옵션을 사용한 경우)
문제 해결에 필요한 도움말이 필요할 경우에는 에러(예 그림 4, "UMR: Uninitialized memory read")를 선택한 후 물음표를 클릭합니다.혹은 Actions 메뉴에서 그림 5처럼 Explain message를 선택합니다.
그림 5: Actions 메뉴의 메뉴 항목
그림 6처럼 UMR 에러 메시지 관련 정보가 나타납니다.
그림 6: UMR 에러 메세지에 대한 설명
도움말을 통해서, Purify가 탐지한 문제에 대한 해결책을 아래 처럼 결정할 수 있습니다:
- 정의되지 않은 lower 변수 값을 사용하는 celsius 변수에 대한 assignment 라인을 삭제합니다. (celsius assignment 라인을 lower 변수 정의 이후로 옮길 수도 있지만 여기선 그럴 필요가 없습니다) 이는 Purify가 분석한 UMR 문제를 해결합니다.
celsius = lower + 10;
- fahr 변수에 대한 free 함수를 호출하여 fahr 변수에 할당된 메모리를 해제합니다. 이는 Purify가 분석한 메모리 누수 MLK를 해결합니다.
문제를 해결한 뒤, Purify를 다시 적용하여 문제가 처리되었는 지 확인하십시요. 그림 7처럼 문제 해결을 확인할 수 있습니다.
그림 7: 문제 해결 후의 Purify 분석 결과 화면

에러가 해결되었고 메모리 누수를 잡았습니다. 프로그램은 이제 좋은 상태입니다.
그림 7: 문제 해결 후의 Purify 분석 결과 화면
에러가 해결되었고 메모리 누수를 잡았습니다. 프로그램은 이제 좋은 상태입니다.























